
Imagine we’ve just created the perfect new CRM. Before we go live, our next job is to import the 1,000,000 contacts from our legacy CRM system. There is a limited window in which the system can be down and the users expect their data to be there seamlessly when they log in on the first day… So how can we get data in as fast as possible?
One way is to use some of the off-the-shelf tools (Kingswaysoft, Azure Data Factory, Scribe etc) that have high throughput as a feature, but how do they work?
In this article, I’m going to explain how this works behind the scenes in these tools, but at the same time, show you how you can do it yourself.
How we’re going to do this
As always, I’m going to shamelessly promote my PowerShell module Rnwood.Dataverse.Data.PowerShell by using this to show how to do it with this. This post assumes you know how to install it and get connected up so see previous posts and the docs for info about getting started.
Your mileage will vary!
The results presented here are based on this very specific and simple scenario and aren’t that scientific (I didn’t repeat X times etc). The conclusions can change depending on the table and many other things. My numbers were against a dev environment, so I expect even better results for prod envs with many licenced users.
Make sure to test your own scenario and draw your own conclusions .
I have linked to the script you can adapt at the bottom of this post.
Also make sure to understand the Dataverse service protection limits , request limits and what will happen once you hit those. This is super important if you are planning a big migration.
Getting some test data to work with
In a real implementation, the data would likely come directly from the system you are migrating from or some extract of it. PowerShell is great for this. You can consume data from almost any source - databases, APIs, CSV/XML/JSON files in local or cloud storage.
That’s not the focus of this article, so instead we’re going to need some test data.
With a bit of help from AI, I knocked up this script to generate N simple contact records using random values and write them to a contacts.json file.
In the example scripts below, we will refer to this data using $contacts after reading and transforming that data like this:
$records = Get-Content -encoding UTF8 "contacts.json" `
| ConvertFrom-Json `
| ForEach-Object {
[PSCustomObject]@{
firstname = $_.FirstName;
lastname = $_.LatName;
emailaddress1 = $_.Email;
telephone1 = $_.PhoneNumber
}
}
(This shows how we can reshape the data easily using PowerShell).
So what’s the challenge?
The fundamental thing that makes getting a large number of records into Dataverse slow is that many naive approaches/tools do it one record at a time. Each request sends just one record to the server, it is then processed and the response must come back before the next one is sent:

What’s the problem with this?
Each request and response cycle carries overhead as the message travels to the server and back. When this is added up over a large number of records, it can make a big period of dead time when nothing useful is happening on the server (Dataverse). Those are the flat lines on the chart above.
Let’s use Rnwood.Dataverse.PowerShell to insert the records one-by-one and see how long it takes. (We have to specify a -batchsize 1 to force it to use this approach because it’s not the default):
$contacts `
| Set-DataverseRecord -connection $connection -tablename contact -batchsize 1
So how long would this take if we were patient enough?
We can get a throughput of around 2 records per second, so 1M records like this would take around 136 hours. Oh no! That’s a week-long outage.
Solution 1 - Batching
So how can we make sure the server stays busier and reduce the overheads?
To implement batching, programs use ExecuteMultipleRequest (and the CreateMultipleRequest/UpdateMultipleRequest/UpsertMultipleRequest variations ) or the equivalent batch requests in the web API .
As part of these request types, multiple records are sent in one go. So the overhead at the start and end is only incurred once:

On our virtual timer, we’ve gone from 900ms to only 700ms for the same 3 records.
With Rnwood.Dataverse.Data.PowerShell batching is on by default. We simply need to remove the -batchsize 1 we added above to return to the default batch size of 100:
$contacts `
| Set-DataverseRecord -connection $connection -tablename contact
To choose a specific batch size instead, we merely need to specify the -batchsize X parameter like this:
$contacts `
| Set-DataverseRecord -connection $connection -tablename contact -batchsize 50
And here is the effect that various batch sizes have on our test scenario:

The general trend for this test was that up to as we increased batch size, it gave us a better result. But there was a limit at around 250 beyond which it was slower.
We saw the highest throughput at 250 records/batch and we’ve got the time it will take for our 1M records down to 42 hours, but can we do better with a different approach?
Solution 2 - Parallelism
This time instead of sending the requests in batches, we’ll send several requests concurrently, each with one thing to do:

Notice, that we are still using 700 of our virtual time units, but this time, we managed to process 4 records. And if had drawn more than 2 threads, imagine that would be many more.
To achieve this, the requests we make are nothing special. We just need to use whatever app/language we have and tell it we would like to run several of these in parallel.
For Rnwood.Dataverse.Data.PowerShell, we can use the built-in facility in PowerShell to parallelise things:
$records `
| ForEach-Object -ThrottleLimit 8 -parallel {
Set-DataverseRecord -Connection (($using:connection).Clone()) -TableName contact -BatchSize 1 -CreateOnly -verbose
}
This will create up to 8 threads and run one request at a time in each of them.
What is the (($using:connection).Clone()) bit about?
Each connection (from the Dataverse SDK) can only be used by one thread at a time, so we have to make sure each parallel thread gets their own, or they will simply wait until the connection is free; defeating the object of parallelisation.
Here’s what the results for the real test look like testing this with various degrees of parallelism:

So, the general trend is the more threads we use, the better the results. Although not shown here, there will be a limit when this is no longer true. Dataverse limits how far we can push this as part of the service protection limits but also reports a recommended degree of parallelism to help avoid that.
Based on our best result of 33RPS, that now gives us a record time of 8 hours for the 1M records. Not bad, but can we go even further?
Solution 3 - Parallelism with Batching
The next approach combines the two previous ones, sending batches of records and then doing that in parallel across several threads:

This time we managed to process 6 records in the 800ms virtual time units. And imagine again, if there were more threads.
Here’s how we can do this using Rnwood.Dataverse.Data.PowerShell:
$records `
`
# Divide up the records into 8 chunks (needs PowerShell.Chunks module) `
| Get-Chunk -size ($records.Length/8) `
`
# Run a thread for each chunk `
| ForEach-Object -ThrottleLimit 8 -parallel {
# Process each record from the chunk
$_ `
`
# ..and process them in batches
| Set-DataverseRecord -Connection (($using:connection).Clone()) -TableName contact -BatchSize 25 -CreateOnly -verbose
}
That’s pretty easy!
How does that change our real results?
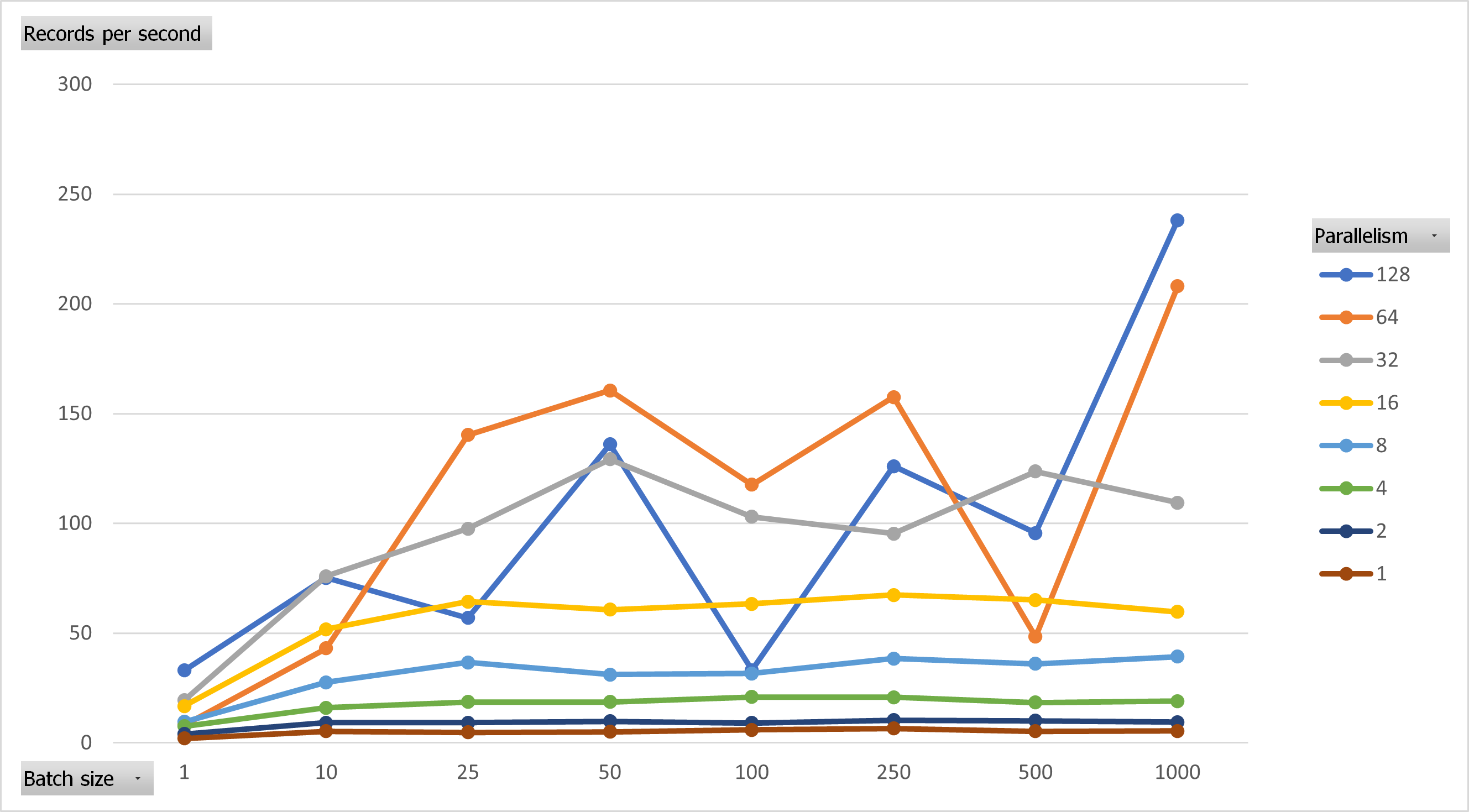
Wow! ~250 records/second means we could import our 1M records in just 1.1 hours.
So solution 3 always with 250 in batch and 128 threads?
Probably not!
As noted at the top of this post, your results will vary enormously depending on your exact scenario. Make sure to test and compare so you know what works best.
If you’re going to do something like this for real, don’t forget:
-
Making the processing of each record idempotent . You probably want to use alternate keys for that.
-
Handling/logging errors (although this solution already handles some retrying transparently)
-
Lots of other things you might want to think about covered in the MS docs here
Footnote
For reference here’s the full script I used to run the benchmarks shown in the charts .